| 序言:
2013年张宏伟(飞萌重庆)就创制了第一版萌式围棋,当时创制萌式围棋的目的是:为《萌玄道》哲学、当代《一分为三论》哲学、《道德经》三生万物三分化诠释、《太玄经》三分图式……等形而上的“三分法哲学”创制一个形而下的象征物。经过我多次修改完善,目前最新萌式围棋规则是2022年版。萌围棋比较复杂和烧脑,一局19路萌围棋,花子可能多达几十个(每10手棋2个花子),而每个花棋串及其紧邻棋串又可能是一个在“上层三变”中变化或振荡的“三变多尾狐(争花棋形)”。三变多尾狐的脸谱身色(花棋串的上层属性)的变化或振荡及相应棋局的变化和逻辑推理极为复杂。人类棋手实际对弈萌围棋时,当棋局中花棋串的上层属性发生变化时,但不做相应的变换和标识,以这样的直弈棋局模式对弈,对人类棋手而言有很大难度,人类棋手需要花费很多脑力用于花棋串上层属性的记忆和重复思考判断上,人类棋手很容易心疲眼花脑蒙圈,观众看棋也累,需要自己判断花棋串的上层属性。
在没有推出人类棋手以全息棋局模式(花棋串上层属性进行相应标识)对弈萌围棋前,人类棋手要实现萌围棋的对弈有很大难度,因此,我2017年又创制了萌围棋的简化版——飞弹围棋来探求其是否可以做为人工智能新的测试棋种。但是飞弹围棋扔飞弹(下花子)的手数次序不固定,棋局更加“无常”,胜负偶然性也更大。
当2022年我正式推出人类棋手以全息棋局模式(花棋串上层属性进行相应标识)及9路或13路小棋盘对弈萌围棋后,人类棋手对弈萌围棋也有了可行性。虽然萌围棋比同等棋盘大小的围棋难度有所增加,但是随着萌围棋相关知识经验(如新定式、新手筋……等)的积累和掌握,以全息棋局模式对弈萌围棋也会由初期的陌生而困难变得相对熟悉而容易。而萌围棋下花子的手数次序固定,棋局更加“有常”,胜负偶然性相对飞弹围棋更小,输赢主要凭棋手的棋力。
《飞弹三色围棋与人工智能》一文是我以前所写,但是我目前主推萌围棋和着重探讨萌围棋做人工智能新的测试棋种的可能性,其详情可阅读《萌围棋M3Go与人工智能》一文。(2022-04-12)
正文:
2010年代初期以来,围棋人工智能程序凭持“深度学习(深度卷积神经网络)和蒙特卡洛树搜索”两大技术在棋力上取得了很大提高。在2016年和2017年韩国围棋九段棋手李世石、中国围棋九段棋手柯洁分别与人工智能围棋程序“阿尔法围棋”(AlphaGo)之间进行了两场影响较大的“围棋人机大战”。第一场“围棋人机大战”,于2016年3月9日至15日在韩国首尔进行,阿尔法围棋以总比分4比1战胜李世石;第二场“围棋人机大战”,于2017年5月23日至27日在中国嘉兴乌镇进行,阿尔法围棋(AlphaGo)以总比分3比0战胜当时围棋世界排名第一的柯洁。目前顶级围棋AI已经远超人类顶级高手(大约可以让人类高手2子)。
那么,飞弹围棋(每方3个飞弹/花子)人工智能程序的训练难度有多高呢?计算机人工智能在传统两色围棋领域棋力一飞冲天所凭持的“深度学习、蒙特卡洛树搜索”两大技术,在新的飞弹围棋领域的泛化能力如何?计算机飞弹围棋程序棋手与人类棋手同台竞技、共同演进,其各自棋力递增情况又会如何?
飞弹围棋对局中放弃下飞弹就成为围棋对局,也即围棋变化集合是飞弹围棋变化集合的子集,这里的变化集合可以用状态空间复杂度(无次序手数标识的棋局局面图的数量)和博弈树复杂度(有次序手数标识的棋局局面图的数量)来表征。
围棋状态空间复杂度(含不符合规则的状态)为:3^361≈10^172;
飞弹围棋状态空间复杂度(要用到排列组合公式计算)为:
A、只有1个飞弹的情况(其它5个飞弹未使用),则有361*3^360(≈120*10^172,围棋状态空间120倍);
B、只有2个飞弹的情况(其它4个飞弹未使用),则有361*360/2*3^359;
C、只有3个飞弹的情况(其它3个飞弹未使用),则有361*360*359/6*3^358;
D、只有4个飞弹的情况(其它2个飞弹未使用),则有361*360*359*358/24*3^357;
E、只有5个飞弹的情况(其它1个飞弹未使用),则有361*360*359*358*357/120*3^356;
F、只有6个飞弹的情况(其它0个飞弹未使用),则有361*360*359*358*357*356/720*3^355(≈4*10^9*10^172,围棋状态空间40亿倍);
围棋博弈树复杂度(含不符合规则的次序)约为:361!(361阶乘),其值比3^361≈10^172还大得多。
含有花子的博弈树就是飞弹围棋相对围棋增加的博弈树复杂度,飞弹围棋博弈树复杂度不好估算,但是比围棋博弈树复杂度会有大量增加。
AlphaZero系统使用的计算机围棋规则是Tromp-Taylor规则,Tromp-Taylor规则与中国围棋规则基本等效。Tromp-Taylor规则编制为程序代码,则可以实现合法走棋、提子、禁着判断及胜负判断。计算机进行对弈及蒙特卡洛模拟对弈就需要程序化的Tromp-Taylor规则支持。
Tromp-Taylor(围棋逻辑)规则表述简洁,使用了数学中的图论思想。Tromp-Taylor规则中文翻译如下(略有增删):
1、围棋是在19x19(361)个交叉点的棋盘上进行,对战者称为黑方和白方;
2、每个交叉点可为黑,白,空三种颜色之一;
3、若存在一条由全是P点颜色的相邻点(水平或竖直)构成的,从P点到某颜色为C的点的路径,就称某颜色不为C的点P为可“到达C”;
4、将所有不能“到达空”的某种颜色的点染为空,叫做“清除”那种颜色(也即实现提子效果);
5、从空白棋盘开始,双方交替“落子”,黑方先走;
6、“落子”要么是“弃权/下虚着/Pass”,要么是使得全局不和以往重复的一次“落子”;
7、“落子”由如下步骤组成:首先将一个空点染为己方颜色,如果可以“清除”对方颜色,则清除对方颜色,(如果不能“清除”对方颜色,但可以清除己方颜色,则需要重新落子/落子点为禁着点);
8、当出现两次连续的“不走”时,棋局结束;
9、某一方的点数等于此方颜色的点数加上只“到达”这一颜色的空色点数;
10、点数高的一方获胜。双方点数相等为平局。
可以认为围棋只有1套逻辑规则:1、Tromp-Taylor(围棋逻辑)规则。
而飞弹围棋具有2套逻辑规则:1、Tromp-Taylor(围棋逻辑)规则;2、花棋串上层属性变化(逻辑)规则。
AlphaZero的深度卷积网络(带残差模块)训练围棋技术的过程,可以看作是以Tromp-Taylor(围棋逻辑)规则产生大量棋谱,然后只告诉神经网络相应棋谱黑方白方最终输赢,让神经网络从这些棋谱中统计出一些较深层、较复杂的棋形(模式)和棋形(模式)相互组合和影响的可以赢棋的统计规律,进一步的也可以认为是让神经网络用统计规律来拟合、逼近演绎逻辑规律和穷举的最优解。
AlphaZero(FlybombGo Zero)的深度卷积网络(带残差模块)训练飞弹围棋技术的过程,可以看作是以Tromp-Taylor(围棋逻辑)规则和花棋串上层属性变化(逻辑)规则产生大量棋谱,然后只告诉神经网络相应棋谱黑方白方最终输赢,让神经网络从这些棋谱中统计出一些较深层、较复杂的棋形(模式)和棋形(模式)相互组合和影响的可以赢棋的统计规律,进一步的也可以认为是让神经网络用统计规律来拟合、逼近演绎逻辑规律和穷举的最优解。
飞弹围棋是规则中嵌套规则,游戏中含有游戏(子游戏),飞弹围棋中花棋串的上层属性变化规则和判断,就是围棋规则中嵌套的规则、围棋游戏中嵌套的子游戏。相比于AlphaZero训练围棋技术,AlphaZero(FlybombGo Zero)训练飞弹围棋技术的难度将增大。 而能否正确判断飞弹围棋中花棋串的上层属性,将在很大程度上决定能否下好飞弹围棋。
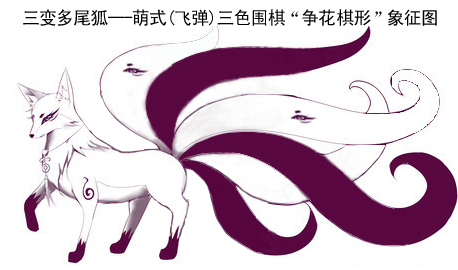
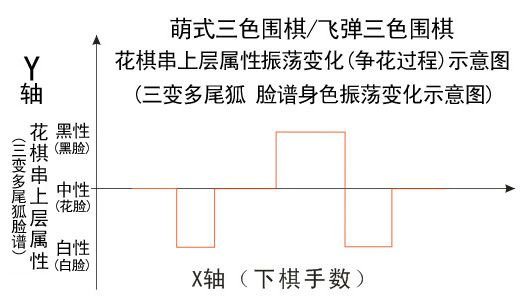
飞弹围棋中的花棋串和其紧邻棋串(争花棋形)也可以比喻为一个“三变多尾狐”,与花棋串紧邻的黑棋串和白棋串就是三变多尾狐的“黑尾巴和白尾巴”,这些黑尾巴和白尾巴的多少和有无“眼睛斑纹(私眼)",将决定此三变多尾狐是:“黑脸狐(黑身狐)”,“白脸狐(白身狐)”,还是“花脸狐(花身狐)”? 而且三变多尾狐的三种脸谱身色(花棋串的上层属性)可能会来回振荡变化多次,象川剧“变脸”、或象电路中的振荡电流一样。《西游记》中的孙悟空有地煞七十二变,猪八戒有天罡三十六变,飞弹围棋中的花棋串则有上层三变。花棋串上层属性振荡变化的过程就是黑棋和白棋对花棋(花棋所占棋盘点和关联利益)进行反复争夺的过程,此现象和过程也可以简称为“争花”。争花以三变多尾狐棋形(争花棋形/花棋串和其紧邻棋串)为基础,三变多尾狐的脸谱(身色)振荡变化过程就是争花过程。其象征图和示意图如下:
Michael Nielsen著的《神经网络和深度学习》中,关于“神经网络可以计算任何函数”的说法有两个提醒:
第一点,这句话不是说一个网络可以被用来准确地计算任何函数。而是说,我们可以获得尽可能好的一个近似。比如可以通过增加隐藏层的数量,提升近似的精度。
第二点,就是可以按照上面的方式近似的函数类其实是连续函数。如果函数不是连续的,也就是会有突然、极陡的跳跃,那么一般来说无法使用一个神经网络进行近似。这并不意外,因为神经网络计算的就是输入的连续函数。然而,即使那些我们真的想要计算的函数是不连续的,一般来说连续的近似其实也足够的好了。如果这样的话,我们就可以用神经网络来近似了。实践中,这通常不是一个严重的限制。(摘引完)
神经网络训练所采用的反向传播算法(BP)需要根据损失函数和链式求导法则,反向逐层计算损失函数对权重的导数。 如果将飞弹围棋中落子情况(输入)和花棋串的上层属性变化(振荡)引起的地域点数出入情况(输出)抽象为函数,这个函数就是一个存在有突然、极陡跳跃的非连续函数,其对应的损失函数也是一个存在有突然、极陡跳跃的非连续函数。而在非连续函数突变和跳跃处是不能求导的,但是否有一个连续函数来近似它?并且深度卷积神经网络来计算它也会表现得足够好呢?
花棋串及其紧邻棋串可能是一个在“上层三变”中来回振荡变化的“三变多尾狐(争花棋形)”,花棋串上层属性出现突变和跳跃所需要的下棋手数往往很长,而且花棋串上层属性还可能来回变化多次,因此,我个人目前判断深度卷积神经网络来计算处理飞弹围棋有很大难度。
人类智能有两大方法:归纳法和演绎法,两者互为补充。
而目前围棋AI长于依凭大数据的统计规律(归纳法),表现得远超人类,其泛化功能与人类的演绎法有较大区别,致使围棋AI在复杂征子及大龙对杀时,有时会出现人类看来的低级错误。
AI能仅依凭大数据的统计规律(归纳法),破茧成蝶吗?
演绎逻辑推理与统计概率做判断的区别,可以黑方A大龙与白方B大龙对杀为例:
人类棋手是用的演绎逻辑推理,常用的是亚理士多德的三段论式推理:
大前提——可略表述为“长气杀短气”:
小前提——比较A大龙和B大龙的气;
结论————杀龙情况。
设该黑方行棋,则黑方就会数出A大龙和B大龙的气数,令为X气和Y气,并进行逻辑判断:
当X=Y,
则黑方会立即按照杀白龙的紧气序列进行紧气,这个紧气序列的末端就是提吃白方大龙。
但AlphaGo等不是这样的,它们并没有归纳出“长气杀短气”的逻辑规则,也没有产生严密数气比气的程序模块,而是基于统计概率来判断的。
其深度卷积神经网络是根据较深层、较复杂的棋形(模式)和棋形(模式)相互组合和影响的统计规律,给出落子点概率和落子点的胜率来判断。
如果黑方为AlphaGo等,它要成功杀白龙,那么前述那个紧气序列中的所有点都必需是第一高概率点,只要其中一个不是第一高概率点,那么就会杀龙不成功。
蒙特卡洛树搜索其实也是基于概率统计的。它运作好比是将深度卷积神经网络给出的每手棋的前10位概率点都模拟试下一遍,然后根据试下结果,调整前述紧气序列,多数情况下蒙特卡洛树搜索会把紧气序列调整正确,但有时它也不能正确调整。
在国际象棋中,AlphaZero训练4小时大比分击败2016 TCEC冠军程序Stockfish,千场只输155场。
在日本将棋中,AlphaZero训练2小时击败了2017年CSA世界冠军程序Elmo,赢得了91.2%的比赛。
在围棋中,AlphaZero训练30小时就超越了与李世石对战的AlphaGo,赢得61%的比赛。
DeepMind说,现在AlphaZero已经学会了三种(国际象棋、日本将棋和围棋)不同的复杂棋类游戏,并且可能学会任何一种完全信息博弈的游戏,这“让我们对创建通用学习系统的使命充满信心”。
微软亚洲研究院资深研究员杨懋、主管研究员秦涛所写的《AI研究和实用化,为何从棋牌开始?》一文中有如下文字:AI算法在研究棋艺的过程中不断精进和提升,会带来更多设计上的创新,从而在根本上提升人工智能算法的能力和适用范围。…棋类也很适合作为新的AI算法的标杆(Benchmark)。…棋牌类AI的成功和突破能够启发AI在其他方面的研究和应用,…推动人工智能去攻克一个又一个技术和应用的“高地”。
AlphaZero架构能在缺乏“演绎法”的情况下快速攻克含有多层规则(多层逻辑)的飞弹围棋吗?站在“围棋巨人”肩上的飞弹围棋,应该还是可以尝试做一做人工智能算法的新的测试棋种吧! |