最近正在学习、领悟《深度卷积网络:原理与实践》,本书作者彭博,曾在围棋吧发布《28 天自制你的 AlphaGo》的帖子。这本书的内容也是对AlphaGo系列计算机围棋原理论述得较为深入和细化的一本书。以下我将对本书的内容做一些学习摘要和理解论述,以期能初窥AlphaGo系列计算机围棋程序架构运用于太玄围棋的情况。由于本人学识所限,对相关内容的理解论述,错误再所难免,还希望有内行和方家热心指正。
《深*》作者自己构建了一个简化的神经网络,用来训练小狗(计算机围棋),本神经网络的输入只采了用8个特征层,但其原理和原版AlphaGo是相同或类似的。《深*》选摘:
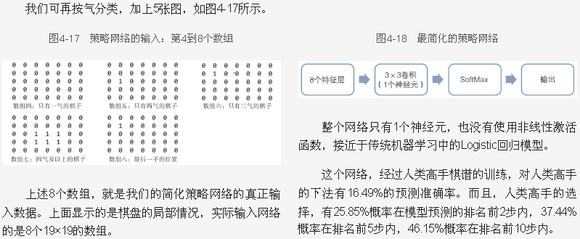
说明一下:作为初始输入的8个特征层(8个数组),是由另外的程序模块来对棋局图进行提取、转化,与卷积核卷积产生的特征图(其实也是数组)的产生方式是不同的。再说明一下,原文:整个网络只有1个神经元,是指对每个特征层只用1个卷积核(3*3卷积核)卷积。
然后把大量人类棋谱拿来作为训练神经网络的数据,也即将这些棋谱中的每个局面分别产生8个初始特征层,并输入神经网络进行训练。一局棋(一局棋谱)有多少手数就对应多少个局面。数据训练完成后,就会得到8个训练好的3*3卷积核,其实也是3*3的二维数组,此二维数组的9个元素值,也就是训练所得的权重。例如,作者训练好的8个卷积核中的其中两个卷积核情况如下:
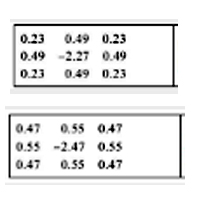
小狗(计算机围棋)下棋方法就是:
当人类对手下完一手棋后,小狗就将这个局面图,提取、转化为前述的8个初始特征层,然后用此前训练好的8个卷积核分别对8个初始特征层进行卷积,然后将8个结果(8个二维数组)相同位置的值加起来,并经过SoftMax函数(离散概率分布的梯度对数归一化)运算,就输出了下一手棋在棋盘上361点各点的落子概率,概率值最大的点即为小狗选择的落子点。
对计算机围棋的策略网络的训练就是提高其预测高水平棋谱中胜方落子点的概率。
中国从古代就存在着《周易》(一分为二/太极体系),同时也存在着《太玄》(一分为三/太玄体系),只是后者影响力较前者小得多。
当代一些学者也在试图构建《一分为三论》哲学(可简称三分法哲学),如:庞朴、周德义等。我个人构建的《萌玄道》也可以认为是“当代一分为三论、古代重玄学和道家哲学的结合与创新”。
三分法哲学、三值逻辑等都是有其意义的。三值二进制计算机、三值三进制计算机,其意义还需要在发展中来拓展和体现吧。但新生事物的发展又是十分艰难的。
原始AlphaGo也需要蒙特卡洛树搜索,
其中策略网络计算当前的落子位置概率,价值网络则计算落子位置的最终胜率,蒙特卡洛树搜索(MCTS)则利用这两个结果进行搜索,策略网络可削减搜索宽度,价值网络可削减搜索深度,并最后给出最终的落子方案。
关于蒙特卡洛树搜索转点资料,《现代计算机围棋基础》摘要:
……蒙特卡洛树搜索,其核心可以体现在以下5个方面:
1、从数学模型上,围棋的博弈问题可以形式化地描述为一个大状态空间上的马尔科夫决策过程;
2、围棋博弈问题所对应的大状态空间上的马尔科夫决策过程可以有效地通过蒙特卡洛规划方法进行计算而获得近似最优解;
3、UCT算法有效地提高了蒙特卡洛规划方法的计算效率;
4、在蒙特卡洛规划中使用适当的围棋领域知识有助于提高蒙特卡洛规划方法的收敛速度;
5、蒙特卡洛规划需要使用高性能计算,而计算机科学中硬件技术和软件技术的发展为此提供了必要条件。
……
现代的蒙特卡洛树搜索算法需要使用大量的围棋知识,这些围棋知识通常是以模式的形式出现的。模式的自动获取、模式价值的定量评估、模式之间搭配关系,以及模式的匹配效率都是现代计算机围棋领域中的重要问题。
……
蒙特卡洛方法,也称为计算机随机模拟方法,是一种基于概率统计理论为指导的非常重要的数值计算方法。……
现代计算机围棋的一个基本思想就是把蒙特卡洛方法应用于围棋局势评估。……
具体来讲,蒙特卡洛对弈是让程序在当前局面的所有可下点中随机选择一个点摆上棋子,不断重复这个随机选择可下点的过程,直到双方都没有可下点,即对弈结束,再把这个最终状态的胜负结果反馈回去,作为评估当前局面的依据。
……在所有可下点中随机选择一个,当然,这样选择出来的点随机效果是最好的,不过从另一个角度来讲,随机性的增加也会带来收敛速度的降低。围棋的搜索空间也意味着几百万次的模拟也只能覆盖搜索树很小的一部分,因此,在随机策略中加入知识去加快其收敛速度是十分必需的。(摘引完)
演绎逻辑推理与统计概率做判断的区别,可以黑方A大龙与白方B大龙对杀为例:
人类棋手是用的演绎逻辑推理,常用的是亚理士多德的三多段论式推理:
大前提——可略表述为“长气杀短气”:
小前提——比较A大龙和B大龙的气;
结论————杀龙情况。
设该黑方行棋,则黑方就会数出A大龙和B大龙的气数,令为X气和Y气,并进行逻辑判断:
当X=Y,
则黑方会立即按照杀白龙的紧气序列进行紧气,这个紧气序列的末端就是提吃白方大龙。
但AlphaGo等不是这样的,它们并没有归纳出“长气杀短气”的逻辑规则,也没有产生严密数气比气的程序模块,而是基于统计概率来判断的。
其深度卷积神经网络是根据较深层、较复杂的棋形(模式)和棋形(模式)相互组合和影响的统计规律,给出落子点概率和落子点的胜率来判断。
如果黑方为AlphaGo等,它要成功杀白龙,那么前述那个紧气序列中的所有点都必需是第1高概率点,只要其中一个不是第1高概率点,那么就会杀龙不成功。
蒙特卡洛树搜索其实也是基于概率统计的。它运作好比是将深度卷积神经网络给出的每手棋的前10位概率点都模拟试下一遍,然后根据试下结果,调整前述紧气序列,多数情况下蒙特卡洛树搜索会把紧气序列调整正确,但有时它也不能正确调整。
关于UCT算法,oyd在csdn网《围棋AI之路(一)理论》选摘:
(蒙特卡洛UCT算法)一个假定,我要选的最大值是在我的最大分支里面。而实际上一个最有钱的城市里不一定住着最有钱的人,因此,这个假定不一定合理,不过无所谓了,就算找出来的不是最有钱的,也不会太平庸,何况我面对的是一个概率,而不是确切的多少钱,如果你这个分支整体上都表现很差的话,我凭什么相信你呢?(摘引完)
前述蒙特卡洛树搜索可能不能正确调整紧气序列的原因:
1、正确紧气序列点之一在深度卷积神经网络给出的每手棋的前10位概率点之外;
2、蒙特卡洛树搜索也收敛到了非最优序列上了。
在训练时间、训练量不充分的情况下,对于最简单的征子,双方没有任何接应,被征吃一方最后在棋盘边角被征死的那种,一般Zero算法的计算机围棋(没有加入工处理征子的算法和模式)可以通过蒙特卡洛树搜索MCTS算法得知最后的结果。但是对复杂一点的征子,比如:1、带远方引征接应的征子;2、与围棋其它技术手法(滚打包收、倒扑等)结合的征子,Zero算法的计算机围棋一般就很难正确判断和处理。可以说征子及复杂征子是困扰Zero算法的计算机围棋的顽疾。
《深*》原文摘引:

例如:2018年7月16日腾讯世界人工智能围棋大赛复赛第4轮,第2局绝艺VS星阵,绝艺执黑,星阵围棋执白,绝艺就出现判断、处理复杂征子的缺陷。棋局如下:

绝艺第71手下出了跑征子的错误着法,星阵第72手正确应对后,绝艺是乎有所“醒悟”,不再跑征子,但由于损失较大,此后进行至第78手,绝艺就因为判断胜率太低,而早早认输。
如果绝艺第73手继续跑征子会怎么样呢?情况演示如下:
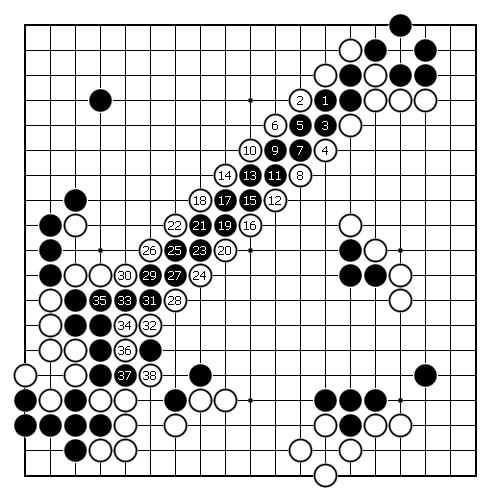
(黑1=黑73,其余类推),至第38手,黑棋被征吃的长串大龙被提吃(被提吃黑棋串暂未清空)。这就是一个复杂的征子情况。
绝艺指导A 在腾讯野狐围棋对弈平台上,让2子 黑贴3又1/4子,与众职业高手对弈,众职业高手已然是一胜难求。但2018年12月4日,绝艺指导A VS 王元均(职业九段)时,就因为出现征子缺陷而输棋,本棋局如下:

绝艺指导A从第129手开始断断续续征吃黑棋串至第153手,黑第154手(红三角处)连接接应的黑子,至绝艺指导A征子失败,此后再下了4手棋,绝艺指导A即认输。
2019年7月26日,吃喝玩乐 VS 绝艺指导A,让2子 黑贴3又1/4子,此对局绝艺指导A同样出现类同上局的征子缺陷而输棋,绿线所示白棋串处于被黑棋叫吃的状态,绝艺指导A早就应该没有了征吃黑棋的必要和可能。本棋局如下:

《深*》原文摘引:


人类智能有两大方法:归纳法和演绎法,两者互为补充。
而目前围棋AI长于依凭大数据的统计规律(归纳法),表现得远超人类,其泛化功能与人类的演绎法有较大区别,致使围棋AI在复杂征子及大龙对杀时,有时会出现人类看来的低级错误。
AI能仅依凭大数据的统计规律(归纳法),破茧成蝶吗?
AlphaZero架构能在缺乏“演绎法”的情况下快速攻克含有多层规则(多层逻辑)的太玄围棋吗?
DeepMind说,现在AlphaZero已经学会了三种不同的复杂棋类游戏,并且可能学会任何一种完全信息博弈的游戏。
AlphaZero架构需要新的测试棋种,这是AI(含AlphaZero)成长和科学实证所需要的。
太玄围棋站在”围棋巨人“的肩上,应该尝试做一做这个新的测试棋种吧。
AlphaZero和AlphaGo Zero相比,架构及算法大体相同,AlphaZero只是做了一些实用于通用化的小调整。目前AlphaZero已经学会了国际象棋、日本将棋、中国围棋等三种不同的复杂棋类游戏,并表现出超越人类棋手和传统程序棋手的强大棋力。下面就以AlphaZero架构及算法应用于太玄围棋的可能情况和效果进行初步的分析、探讨。
AlphaZero系统使用的计算机围棋规则是Tromp-Taylor规则,Tromp-Taylor规则与中国围棋规则基本等效。Tromp-Taylor规则编制为程序代码,则可以实现合法走棋、提子、禁着判断及胜负判断。计算机进行对弈及蒙特卡洛模拟对弈就需要程序化的Tromp-Taylor规则支持。
Tromp-Taylor(围棋逻辑)规则表述简洁,使用了数学中的图论思想,也很容易转化为计算机代码,终局胜负判断也很方便。
Tromp-Taylor规则中文翻译如下(略有增删):
1、围棋是在19x19(361)个交叉点的棋盘上进行,对战者称为黑方和白方;
2、每个交叉点可为黑,白,空三种颜色之一;
3、若存在一条由全是P点颜色的相邻点(水平或竖直)构成的,从P点到某颜色为C的点的路径,就称某颜色不为C的点P为可“到达C”;
4、将所有不能“到达空”的某种颜色的点染为空,叫做“清除”那种颜色(也即实现提子效果);
5、从空白棋盘开始,双方交替“落子”,黑方先走;
6、“落子”要么是“弃权/下虚着/Pass”,要么是使得全局不和以往重复的一次“落子”;
7、“落子”由如下步骤组成:首先将一个空点染为己方颜色,如果可以“清除”对方颜色,则清除对方颜色,(如果不能“清除”对方颜色,但可以清除己方颜色,则需要重新落子/落子点为禁着点);
8、当出现两次连续的“不走”时,棋局结束;
9、某一方的点数等于此方颜色的点数加上只“到达”这一颜色的空色点数;
10、点数高的一方获胜。双方点数相等为平局。
《深*》原文摘引:

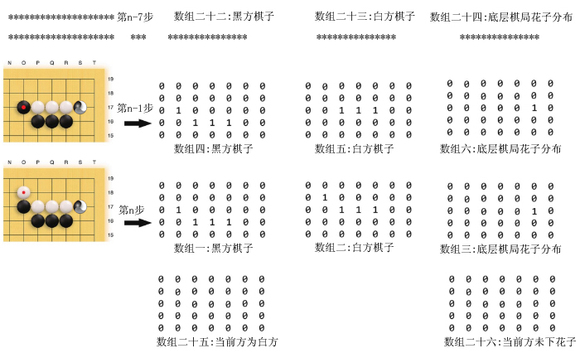
AlphaZero和AlphaGo Zero的神经网络结构相同。AlphaZero的输入也是上述17个19*19的(二维数组)特征层。下面简化局部示例如下:
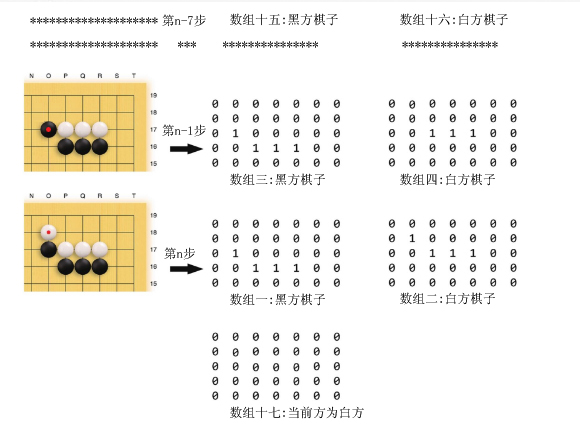
计算机太玄围棋(TrisGoZero)也采用AlphaZero(AlphaGo Zero)的神经网络架构,那么其特征层将增加为26个19*19的(二维数组)特征层。其中增加了8个底层棋局花子分布情况(二维数组)特征层,以及1个当前方本回合是否下了花子(全1表示下了花子,全0表示没有下花子),下面简化局部示例如下:
可以认为围棋只有1套逻辑规则:1、Tromp-Taylor(围棋逻辑)规则。
而太玄围棋具有2套逻辑规则:1、Tromp-Taylor(围棋逻辑)规则;2、花棋串上层属性变化(逻辑)规则。
AlphaZero的深度卷积网络(带残差模块)训练围棋技术的过程,可以看作是以Tromp-Taylor(围棋逻辑)规则产生大量棋谱,然后只告诉神经网络相应棋谱黑方白方最终输赢,让神经网络从这些棋谱中统计出一些较深层、较复杂的棋形(模式)和棋形(模式)相互组合和影响的可以赢棋的统计规律,进一步的也可以认为是让神经网络用统计规律来拟合、逼近演绎逻辑规律和穷举的最优解。
AlphaZero(TrisGoZero)的深度卷积网络(带残差模块)训练太玄围棋技术的过程,可以看作是以Tromp-Taylor(围棋逻辑)规则和花棋串上层属性变化(逻辑)规则产生大量棋谱,然后只告诉神经网络相应棋谱黑方白方最终输赢,让神经网络从这些棋谱中统计出一些较深层、较复杂的棋形(模式)和棋形(模式)相互组合和影响的可以赢棋的统计规律,进一步的也可以认为是让神经网络用统计规律来拟合、逼近演绎逻辑规律和穷举的最优解。
太玄围棋是规则中嵌套规则,游戏中含有游戏(子游戏),相比于AlphaZero训练围棋技术,AlphaZero(TrisGoZero)训练太玄围棋技术的难度将增大。
我个人目前认为:太玄围棋中的争花(黑棋和白棋对花棋串的争夺/三变多尾狐-振荡器结构),对于神经网络而言其难度是高于围棋征子和复杂征子的。
因为:
1、三变多尾狐-振荡器结构的模式(棋形)千变万化,很难用模式(棋形)来总结、提炼、比对、识别,即或人类也很难手工编制计算机算法模块对其进行精确预测判断。
2、争花增多了关联的棋串,增大了所需要的模式识别尺寸,加大了所需要的计算深度和广度。一些布局和中局的中性花棋串,往往到收官(终局)阶段才会急剧“争花”,产生上层属性变化,其中间的间隔手数很长,可能由于计算深度不够,而产生地平线效应,也即在深度搜索n步后取得一个胜率评估值,如果再深算1步或多步,该胜率评估值就会被巨大修正。计算机评估的胜率在短短一手或几手间急剧下滑, 原因是计算机围棋对低概率选点计算不足产生错误下法,发现时为时已晚,例如AlphaGo对李世石第四局第78手——“神之一手”。再例如征子,对计算机围棋而言,就容易产生地平线效应。
3、三变多尾狐-振荡器结构中的花棋串的上层属性可能存在多次往复、突然、极徒的跳跃,其抽象函数也是有突然、极徒跳跃的非连续函数,而神经网络的算法是基于连续函数,用连续函数来近似非连续函数,其精度会降低。对AlphaZero(AlphaGo)而言,就是可能会具有在本算法体系中难以修复的缺陷(Bug),表现出有时犯一些人类看来的低级错误。
网上会有或潜在会有质疑我发明和推进太玄围棋的意义?我下面还是谈点看法:
我此前看过一本书《什么是科学》(作者:吴国盛 北京大学 2016.8)。
在作者的自序中有如下言论:
一百年来,本着我们一向熟悉的实用态度来学习西方的科学,中国的科学也取得了巨大的成就,基本实现了“科学救国”的理想。但是,今天我们面临新的历史使命。中国人在解决了落后挨打、贫穷挨饿的急难之后,要复兴中华文化,成为引领人类文明之未来力量。在这个新的形势下,仍然用实用的态度来对待科学和科学家,就无法真正完成这个新的历史使命。
其中饶毅(北京大学讲席教授、理学部主任)在给本书的序二中有如下言论:
中国人对科学的误解其实更多体现于一种功利主义取向。很多人不了解科学是人类探索、研究、感悟宇宙万物变化规律的知识体系的总称,是对真理的追求,对自然的好奇。
我总结一下,科学发展的两大模式:
模式一:靠兴趣和好奇心推动科学的发展。在此模式下,事先不用“意义和实用性标尺”给“感兴趣和好奇的事物”评级,或者说事先不用“意义和实用性标尺”来给探索行为预设禁区和边界,而给探索活动以最大自由度和发挥空间。这种模式也是一种“广种模式”,在广种中求多收。形象地说,就是欢迎玩出花样、玩出高度,在这些花样和高度中,一定可以从中筛选、发展或挖掘出有意义和有实用性的事物。
模式二:事先就用“意义和实用性标尺”给“感兴趣和好奇的事物”评级,或者说事先就用“意义和实用性标尺”来给探索行为预设禁区和边界,这种模式也是一种“精准模式”。
模式一会存在“广种薄收”现像;模式二会存在“意义和实用性标尺”滥用现象,因为对于新生事物其意义和实用性往往是不能简单预见的。
科学发展的模式一和模式二可以相结合。模式一,也会对探索、推动的新生事物去发展或挖掘其意义和实用性,只是这并不是前提。
“尊生贵养”可以说是道家和当代新道家(包括萌玄道)的核心理念之一。
国学大师张岱年先生曾在《论中国哲学发展的前景》一文中,将中国哲学的精湛深邃的观点(中国哲学基本精神)概括为最重要的四点,其中第一点就是“ 天道生生”。《道德经》有言:“道生之,德蓄之,物形之,势成之。是以万物莫不尊道而贵德。道生德蓄,那么尊道贵德,就含有尊生贵养之意。
尊生,就是尊崇道的创生和化生;贵养,就是贵重德的养育和呵护。
对人类而言,生养子女应当值得尊崇和贵重。泛化理解,则发明革新活动值得尊崇,对优良的发明革新事物的养育呵护,值得贵重。
科学发展的模式一和模式二可以相结合。我下面就针对发明和推进太玄围棋的意义和实用性谈点看法:
1、太玄围棋是站在“围棋巨人”的肩上,状态空间复杂度和博弈树复杂度都比围棋有大量增加,而且太玄围棋满足人类可下,太玄围棋在目前棋类复杂度排名榜中可以直接进入顶级棋类,而文化影响力及软实力就需要各种大大小小的、与时俱进的不同领域的“顶级”文化项目来加分。
2、太玄围棋与传统围棋基因紧密相连,围棋的知识和经验在太玄围棋中都没有作废,可以移值沿用。人工智能这列火车如果能在围棋站台多作停留、继而如果能在太玄围棋站台多作停留,这将加长围棋向世界传播、推广的春天的持续时间。
3、太玄围棋除了拥有黑子、白子对立的两方,还拥有多变的中立方——花子,这样可以对很多社会现象进行更全面、逼真的模拟。例如,人类社会的政治、经济和军事博弈,都常常涉及多变的中立方。因此,太玄围棋可以做计算机深度学习和人工智能的陪练,为人工智能解决一些涉及多方的、复杂的社会问题做初步演练。
4、健身可以有各种健身操,益智也可以有各种棋类游戏,太玄围棋可以说是一种涵有三分法思维模式/方法论/哲学系统的“棋类益智体操”。
5、只要当代《一分为三论》哲学和其关联哲学系统还要继续存在和发展,那么太玄围棋就可以做为它们的一种接地气的象征物。也即形而上的“三分法思维模式/方法论/哲学系统”向形而下转化和延伸的产物和可能产物就包括:太玄围棋、对称三进制(三值)计算机……等,它们可以归于一个共同的模式类,推进太玄围棋的发展就有扩大本模式类及“三分哲学”的影响力、促进本模式类事物及“三分哲学”繁盛的潜在意义。
我在大学及此后一段时间,也曾沉迷于“汉字输入法、对称三进制计算机、计算机新语言、文字改良革新”等构想发明中,但这个工程太宏大、太艰难远非我个人所能掌控和推进,鼓捣一段时间就此封存,但也就此改变了我的人生道路,从此也与发明推广结缘,选择了一条道路,有时真的是虽然艰困,但是当事人也常常不忍心退缩。当然其间和结果的酸甜苦辣、冷暖悲欢、成功失败也需要自我承受了。
下面是我曾经写给自己和发明创新爱好者同道的文章,现在略做修改也发布于此:
“创新是一个民族的灵魂,是一个国家兴旺发达的不竭动力”。“创新才有生命力”,发明创新领域或大或小,或轻或重,但其所需尊从的科学原则和所须凭持的科学精神是共同的。
发明创新及其论证、改良……推广这条路,通常又是一条高风险、高崎岖之路。特别是对个体发明人(业余发明人)而言,综合条件和能力都有很大局限,要发明成功和推广成功是很艰难的。发明创新是一粒希望的种子,希望成真与希望破灭纠缠,而在很多情况下,个体发明人(业余发明人)的个人能力、精力和财力,常常不足以支撑他走完发明创新、论证、改良、论证、改良……、推广(转化)的漫长全程。个体发明人(业余发明人)一定要对自己的创新推广经常做评估和反省,量力而行,进退有据,成功亦喜,失败亦喜。
难、难、难,个人全能难,各方力量整合难,但只要我们还没有失掉发明创新的希望,就还可以继续做一个探索者。但是,做为探索者,就要有付出,只是要根据自身情况,从物质和精神上,把握好一个度,不可过于冒进,或太深陷其中。而执着是个双刃剑,可能助你成功,也可能加重你的失败和损害。但轻松的来也可以轻松的去,如此的探索方式多做做也无妨。 但发明人、革新者常常会不知不觉走入自恋和偏激之中,所谓当局者迷,旁观者清。为此,个体发明人也需要时常提醒并省查自己是否陷入自恋和偏激之中。
感觉和计算决定选择,选择决定命运。个体发明人(业余发明人)要在“棋局”艰难中,培养感觉的敏锐,计算的精深,发明创新活动不过是人生棋局的一个局部,其大小、轻重、厚薄、缓急,坚持还是舍弃,细感觉,深计算,慎选择,愿自我努力,朋友协助,上天眷顾,做个好“棋手”,下个好“对局”。是以之与发明同道共勉!
在商业经济领域,马化腾、丁磊、刘强东……等70后,做出了卓越成就,我这个70后与他们相比差太远太远了。
但是,在文化创新方面:
1、我创建了当代 新道家 流派(道家 新流派)——萌玄道。
2、我为当代/古代“一分为三论”哲学设计了新的视觉图形符号——太玄图和萌脸符(萌符)。
3、我发明了太玄围棋和太玄象棋。
然而,文化创新、文化价值评估、文化推广传播、文化价值开发(文化运营营销),涉及四个领域,一个人要同时在这四个领域做出好成绩很难。
我就在文化推广传播和文化价值开发上遇到了困难,这其实也是我的短板,个人能力有限。
我正处壮年而不是老骥吧。创新了有价值的文化项目,在该项目的文化推广传播和文化价值开发上也应该努力做出较好的成果,但是我不转变观念、不谋求改变,一点机会没有,谋求改变还多少有点机会吧。
对现在的我而言,自己首先就不能在“信心、勇气和行动力”上泄气。不论成败大小,只求不负此生!
|
